There is a particularly CPU bound task I run, building cluster markers for use on a Google Maps API application. There are about 100,000 markers that need to be turned into cluster points on each of the zoom levels that they need to be displayed for on the map.
My current code has a web front end, running on django under mod_wsgi and it uses threads to run long running tasks like this while returning to the browser quickly.
 The clustering job takes about 12 minutes to run and I see that one CPU is doing all the work, while another is doing all the mysql database work.
The clustering job takes about 12 minutes to run and I see that one CPU is doing all the work, while another is doing all the mysql database work.With nothing else significant on the box, load average is about 0.8 (out of a theoretical 8.0 for an 8 core machine).
As an experiment I quickly converted my code to use python 2.6's multiprocessing module to hand the work for each level to a process in a Pool. This kind of job is particularly well-suited as it's easily split into separate parts that don't depend on each other.
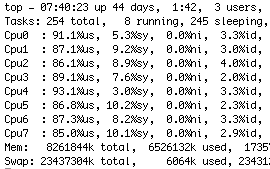 Here you see how top looks running the new code.
Here you see how top looks running the new code. I'm getting excellent utilisation of all the cores and load average is now 6.4 which is using the machine without killing it.
The end result of all this is that my 12 minute, 4 second task now completes in 3 minutes, 16 seconds, so about 3.7 times faster. Now mysql is looking like the bottleneck:

I mentioned that my app runs under mod_wsgi and kicks off threads. For some reason I can't get multiprocessing Pool to work in this environment so I'm running these tests (both single and multi) as command line versions. Here's a dummy implementation to illustrate how I'm using it.
import multiprocessing
import os
import random
import time
def completedCallback(layer):
print("completedCallback(%s)" % layer)
def dummyTask(layer):
print("dummyTask(%s) processid = %s" % (layer, os.getpid()))
time.sleep(random.randint(1,5))
return(layer)
if __name__ == "__main__":
print("processid = %s" % os.getpid())
pool = multiprocessing.Pool()
layers = ("one", "two", "three", "four", "five")
for layer in layers:
pool.apply_async(dummyTask,
(layer,),
callback = completedCallback)
pool.close()
print("pool closed")
pool.join()
print("pool joined")
Here's how it runs (different every time though).
processid = 6651
dummyTask(one) processid = 6652
dummyTask(two) processid = 6653
pool closed
dummyTask(three) processid = 6654
dummyTask(four) processid = 6655
dummyTask(five) processid = 6656
completedCallback(two)
completedCallback(five)
completedCallback(one)
completedCallback(three)
completedCallback(four)
pool joined
Pool() gives you a pool equal to the number of cores on your system (you can ask for more or less if you wish).
You apply_async tasks to the pool as shown, the first argument is a function, then the args to the function and finally a completion callback.
Closing the pool means no more tasks can be added to it. Join causes the main thread to pause until all of the processes have finished.
Pretty easy to use but if you mess up with the arguments to the task it just doesn't work and I haven't figured out how to show what went wrong.
I've converted another tool that does polygon simplification. This one is particularly CPU intensive and this time I'm getting everything possible out of this 8 core box.

The multiprocessing module is easy to use and works well, recommended.
Great walk through. Explains exactly what's needed. Nice of you to include the real performance increases. Thanks.
ReplyDelete